Well, I needed a way to watch the mdstat progress (because a disk just failed …).
|
1 2 3 |
#!/bin/bash watch -n1 cat /proc/mdstat |
Well, I needed a way to watch the mdstat progress (because a disk just failed …).
|
1 2 3 |
#!/bin/bash watch -n1 cat /proc/mdstat |
Well, I have a few movies and series that ain’t represented in TMDB/TVDB. So here’s a little script, that will parse over any video files, check if a thumb file is already present, and if not generate one using ffmpegthumbnailer…
|
1 2 3 4 5 6 7 8 |
#!/bin/bash find /srv/smb/tv/ -name "*.wmv" -o -name "*.avi" -o -name "*.mp4" \ -o -name "*.mkv" | while read file; do if [ ! -f "${file%.*}-thumb.jpg" ] ; then fmpegthumbnailer -i $file -o "${file%.*}-thumb.jpg" -s 0 &>/dev/null fi done |
Well, I recently had to flatten my archive NAS (well only the OS part … *wheeeh*). Since I didn’t have the chance to backup the old settings I had to do everything from scratch … And this time I decided, I wasn’t doing a script but rather the proper way.
I spent a while reading through the Internetz about the various settings until I stumbled upon a Frauenhofer Wiki entry. From there I ended up writing those udev-rules and the sysctl configs…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# Settings from http://www.fhgfs.com/wiki/StorageServerTuning # Set an appropriate IO scheduler for file servers. KERNEL=="sd[a-z]", ATTR{queue/scheduler}="deadline" KERNEL=="sd[a-i][a-z]", ATTR{queue/scheduler}="deadline" # Give the IO scheduler more flexibility by increasing the number of # schedulable requests. KERNEL=="sd[a-z]", ATTR{queue/nr_requests}="4096" KERNEL=="sd[a-i][a-z]", ATTR{queue/nr_requests}="4096" # To improve throughput for sequential reads, increase the maximum amount of # read-ahead data. The actual amount of read-ahead is adaptive, so using a # high value here won't harm performance for small random access. KERNEL=="sd[a-z]", ATTR{queue/read_ahead_kb}="73728" KERNEL=="sd[a-i][a-z]", ATTR{queue/read_ahead_kb}="73728" KERNEL=="sd[a-z]", RUN+="/sbin/blockdev --setra 73728 /dev/%n" KERNEL=="sd[a-i][a-z]", RUN+="/sbin/blockdev --setra 73728 /dev/%n" SUBSYSTEM=="block", KERNEL=="md[0-9]*", RUN+="/sbin/blockdev --setra 663552 /dev/%n" SUBSYSTEM=="block", KERNEL=="md[0-9]*", ATTR{md/stripe_cache_size}="9216" # Optimal performance for hardware RAID systems often depends on large IOs # being sent to the device in a single large operation. Please refer to your # hardware storage vendor for the corresponding optimal size of # /sys/block/sdX/max_sectors_kb. # It is typically good if this size can be increased to at least match your # RAID stripe set size (i.e. chunk_size x number_of_disks): KERNEL=="sd[a-z]", ATTR{queue/max_sectors_kb}="512" KERNEL=="sd[a-i][a-z]", ATTR{queue/max_sectors_kb}="512" KERNEL=="sd[a-z]", ATTR{device/queue_depth}="1" KERNEL=="sd[a-i][a-z]", ATTR{device/queue_depth}="1" |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Settings taken from http://www.fhgfs.com/wiki/StorageServerTuning # To avoid long IO stalls (latencies) for write cache flushing in a production # environment with very different workloads, you will typically want to limit # the kernel dirty (write) cache size. vm.dirty_background_ratio = 5 vm.dirty_ratio = 10 # Assigning slightly higher priority to inode caching helps to avoid disk seeks # for inode loading vm.vfs_cache_pressure = 50 # Buffering of file system data requires frequent memory allocation. Raising the # amount of reserved kernel memory will enable faster and more reliable memory # allocation in critical situations. Raise the corresponding value to 64MB if # you have less than 8GB of memory, otherwise raise it to at least 256MB vm.min_free_kbytes = 262144 |
For now, I’m rather pleased with the results …
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
root:(charon.ka.heimdaheim.de) PWD:/ Wed Jul 09, 15:02:08 [0] > mdadm --detail /dev/md127 /dev/md127: Version : 1.2 Creation Time : Sat Jan 26 18:35:19 2013 Raid Level : raid5 Array Size : 15626121216 (14902.23 GiB 16001.15 GB) Used Dev Size : 1953265152 (1862.78 GiB 2000.14 GB) Raid Devices : 9 Total Devices : 10 Persistence : Superblock is persistent Update Time : Wed Jul 9 15:03:28 2014 State : clean Active Devices : 9 Working Devices : 10 Failed Devices : 0 Spare Devices : 1 Layout : left-symmetric Chunk Size : 512K Name : charon:aggr1 (local to host charon) UUID : 6d11820f:04847070:2725c434:9ee39718 Events : 11186 Number Major Minor RaidDevice State 0 8 129 0 active sync /dev/sdi1 1 8 33 1 active sync /dev/sdc1 2 8 49 2 active sync /dev/sdd1 4 8 65 3 active sync /dev/sde1 5 8 17 4 active sync /dev/sdb1 10 8 97 5 active sync /dev/sdg1 9 8 81 6 active sync /dev/sdf1 8 8 161 7 active sync /dev/sdk1 7 8 145 8 active sync /dev/sdj1 6 8 113 - spare /dev/sdh1 |
And here’s the dd output:
|
1 2 3 4 5 6 |
root:(charon.ka.heimdaheim.de) PWD:/ Wed Jul 09, 14:57:32 [0] > dd if=/dev/zero of=/srv/smb/tmp bs=1G count=100 \ oflag=direct 100+0 records in 100+0 records out 107374182400 bytes (107 GB) copied, 257.341 s, 417 MB/s |
Well, I’ve had my share of troubles with Hetzner, Debian, KVM and IPv6 addresses. After figuring out how to get around the IPv6 neighbor stuff (npd6 for teh win!), I battled with the problem that after restarting (rebooting/resetting – doesn’t really matter) a domain it’s IPv6 address would no longer work.
Well, today I decided to take a closer look. After the reboot, the guest comes up with this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
pinguinfuss:(thanatos.heimdaheim.de/webs) PWD:~ Mon Sep 09, 19:01:27 [0] > ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:96:ed:35 brd ff:ff:ff:ff:ff:ff inet 78.46.37.114 peer 78.46.37.118/32 brd 78.46.37.114 scope global eth0 inet6 2a01:4f8:110:3148::5/64 scope global tentative dadfailed valid_lft forever preferred_lft forever inet6 fe80::5054:ff:fe96:ed35/64 scope link valid_lft forever preferred_lft forever |
A quick peek into ip 6 neigh show reveals this:
|
1 2 3 |
pinguinfuss:(kvm.heimdaheim.de/KVM) PWD:~ Mon Sep 09, 19:02:27 [0] > sudo ip -6 neigh show 2a01:4f8:110:3148::5 dev eth0 FAILED |
At this point I had no idea were to look (I haven’t used IPv6 much), so thanks to a friend I ended up googling whatever dadfailed meant … as it turns out dadfailed indicates that a duplicate address had been detected. A short peek into kern.log/dmesg fuelled that idea:
|
1 2 3 |
pinguinfuss:(thanatos.heimdaheim.de/webs) PWD:/var/log Mon Sep 09, 19:33:46 [0] > sudo grep eth kern.log Sep 9 19:03:25 thanatos kernel: [ 9.150549] eth0: IPv6 duplicate address 2a01:4f8:110:3148::5 detected! |
So, I went on googling IPv6, KVM and duplicate address, and guess what .. I don’t seem to be the only one that has this issue … I haven’t found the root cause of this, but I have a quick fix … I usually don’t assign duplicate IPv6 addresses to multiple domains (each domain has it’s on block of IPv6 addresses), so I ended up writing a short puppet class, that’ll disable the Duplicate Adress Detection for all my KVM guests!
|
1 2 3 4 5 6 7 8 |
class kvm-ipv6-domain { file { 'kvm-ipv6.conf': path => '/etc/sysctl.d/kvm-ipv6.conf', ensure => 'present', mode => '0644', content => 'net.ipv6.conf.eth0.accept_dad=0', } } |
Well, I’ve been moving stuff to my archive NAS, and in case anyone is wondering – the DS213+ actually nearly gets to the 1GE transmission limit… It’s near the CPU limit then anyhow, but … 🙂
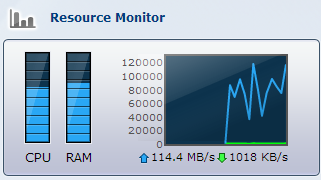
As the title pretty much tells, I’ve been working on fixing the Root-Disk-Multipathing feature of our XenServer installations. Our XenServer boot from a HA-enabled NetApp controller, however we recently noticed that during a controller fail-over some, if not all, paths would go offline and never come back. If you do a cf takeover and cf giveback in short succession, you’ll end up with a XenServer host that is unusable, as the Root-Disk would be pretty much non-responsive.
Guessing from that, there don’t seem to be that many people using XenServer with Boot-from-SAN. Otherwise Citrix/NetApp would have fixed that by now…. Anyhow, I went around digging in our XenServer’s. What I already did, was adjust the /etc/multipath.conf according to a bug report (or TR-3373). For completeness sake I’ll list it here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Multipathing configuration for XenServer on NetApp ALUA # enabled storage. # TR-3732, revision 5 defaults { user_friendly_names no queue_without_daenon no flush_on_last_del yes } ## some vendor specific modifications devices { device { vendor "NETAPP" product "LUN" path_grouping_policy group_by_prio features "1 queue_if_no_path" getuid_callout "/sbin/scsi_id -g -u -s /block/%n" prio_callout "/sbin/mpath_prio_alua /dev/%n" path_checker directio failback immediate hardware handler "0" rr_weight uniform rr_min_io 128 } } |
And as it turns out, this is the reason why we’re having such difficulties with the Multipathing. The information in TR-3373 is a bunch of BS (no, not everything but a single path is wrong, the getuid_callout) and thus the whole concept of Multipathing, Failover and High-Availibility (yeah, I know – if you want HA, don’t use XenServer :P) is gone.
Well, I’ve been tinkering with NGINX for a while at home, up till now I had a somewhat working reverse proxy setup (to access my stuff, when I’m not at home or away).
What didn’t work so far was the DSM web interface. Basically, because the interface is using absolute paths in some CSS/JS includes, which fuck up the whole interface.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<link rel="stylesheet" type="text/css" href="/scripts/ext-3/resources/css/ext-all.css?v=3211" /> <link rel="stylesheet" type="text/css" href="/scripts/ext-3/resources/css/xtheme-gray.css?v=3211" /> <link rel="stylesheet" type="text/css" href="/scripts/ext-3/ux/ux-all.css?v=3211" /> <link rel="stylesheet" type="text/css" href="resources/css/desktop.css?v=3211" /> <link rel="stylesheet" type="text/css" href="resources/css/flexcrollstyles.css?v=3211" /> ... <script type="text/javascript" src="/scripts/uistrings.cgi?lang=enu&v=3211"></script> <script type="text/javascript" src="/webfm/webUI/uistrings.cgi?lang=enu&v=3211"></script> <script type="text/javascript" src="uistrings.cgi?lang=enu&v=3211"></script> <script type="text/javascript" src="/scripts/prototype-1.6.1/prototype.js?v=3211"></script> <script type="text/javascript" src="/scripts/ext-3/adapter/ext/ext-base.js?v=3211"></script> <script type="text/javascript" src="/scripts/ext-3/ext-all.js?v=3211"></script> <script type="text/javascript" src="/scripts/ext-3/ux/ux-all.js?v=3211"></script> <script type="text/javascript" src="/scripts/scrollbar/flexcroll.js?v=3211"></script> |
After some googling and looking through the NGINX documentation I thought “Why don’t I create a vHost for each application that is being served by the reverse proxy?”.
And after looking further into the documentation, out came this simple reverse proxy statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
server { listen 80; server_name syno.heimdaheim.de; location / { proxy_pass http://172.31.76.50:5000/; proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504; proxy_redirect http://172.31.76.50:5000/ http://$host:$server_port/; proxy_buffering off; auth_basic "Restricted"; auth_basic_user_file /etc/nginx/htpasswd; } } |
And as you can see, it works:
Well, I’ve been fiddling with OpenWRT to replace my crappy Vodafone Easybox 602. Up till now I had DD-WRT on the DIR-615’s (yes, two) however recently (I think due to the Synology DiskStation in combination with a WDS setup) I had to filter SSDP broadcasts storms (which in turn kill the Easybox), which isn’t quite so easy on DD-WRT, but rather easy on OpenWRT.
Today I went thinking about VLAN-Tagging and stuff, and I had to figure out the physical to logical port mapping for the DIR-615. So let’s run swconfig dev rt305x show on the DIR-615 after plugging in the RJ45 cable to a port.
Out came this nifty table, which’ll hopefully help me, wrapping my head around this whole VLAN thing.
| physical port | CPU | WAN | WLAN | LAN 1 | LAN 2 | LAN 3 | LAN 4 |
| logical port | 6* | 5 | 4 | 3 | 2 | 1 | 0 |
Keep in mind, the CPU port (or the backplane port, connected with 1000 Base-T FD) is by default in both VLANs as a tagged port.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
config interface 'loopback' option ifname 'lo' option proto 'static' option ipaddr '127.0.0.1' option netmask '255.0.0.0' config interface 'lan' option ifname 'eth0.1' option type 'bridge' option proto 'static' option ipaddr '172.31.76.10' option netmask '255.255.255.0' # option ip6addr 'fixme/64' option gateway 172.31.76.1 option broadcast 172.31.76.255 option dns 172.31.76.30 config interface 'wan' option ifname 'eth0.2' option proto 'dhcp' config switch option name 'rt305x' option reset '1' option enable_vlan '1' config switch_vlan option device 'rt305x' option vlan '1' option ports '0 1 2 3 6t' config switch_vlan option device 'rt305x' option vlan '2' option ports '4 6t' # # IPv6 tunnelbroker.net # #config interface 'henet' # option proto '6in4' # option peeraddr '216.66.80.30' # option ip6addr 'fixme/64' # option tunnelid 'fixme' # option username 'fixme' # option password 'fixme' config interface 'vpn' option proto 'none' option auto '1' option ifname 'tun0' |
Well, I wanted independent SpamAssassin Bayes databases per user (different users, different preferences). For that, RoundCube already set up the Junk folder. However, I wanted the ability (for myself, as well for my other users) to individually mark messages as either Spam or Ham.
Now, as I said before I wanted a trivial way to mark messages as Spam or Ham (without using the command line each time).
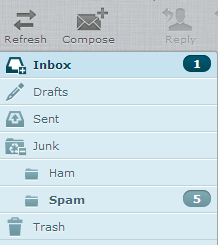
Now, that was the mailbox setup part. Now we do have to do some command line foo (yeah, it’s still necessary) to actually learn the mails as spam or ham. First we need a script, which scans the Maildir for each domain/user separately, and then creates the bayes database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
#!/bin/bash # Script, which allows per-user bayes db's for a dovecot virtual user # setup. sa-learn parses a set amount of folders (.Junk.Spam and .Junk.Ham) for # Ham/Spam and adds it to the per-user db. MAIL_DIR=/var/mail SPAMASS_DIR=/var/lib/spamassassin SPAM_FOLDER=".Junk.Spam" HAM_FOLDER=".Junk.Ham" # get all mail accounts for domain in $MAIL_DIR/*; do for user in $MAIL_DIR/${domain##*/}/*; do mailaccount=${user##*/} dbpath=$SPAMASS_DIR/${domain##*/}/$mailaccount spamfolder=${domain}/${mailaccount}/Maildir/$SPAM_FOLDER hamfolder=${domain}/${mailaccount}/Maildir/$HAM_FOLDER if [ -d $spamfolder ] ; then [ ! -d $dbpath ] && mkdir -p ${dbpath} echo "Learning Spam from ${spamfolder} for user ${mailaccount}" nice sa-learn --spam --dbpath ${dbpath}/bayes --no-sync ${spamfolder} fi if [ -d $hamfolder ] ; then echo "Learning Ham from ${hamfolder} for user ${mailaccount}" nice sa-learn --ham --dbpath ${dbpath}/bayes --no-sync ${hamfolder} fi if [ -d $spamfolder -o -d $hamfolder ] ; then nice sa-learn --sync --dbpath $dbpath # Fix dbpath permissions chown -R mail.mail ${dbpath} chmod 700 ${dbpath} fi done done |
This script is based on work from nesono and workaround.org. Anyhow, the script will scan each user folder (you might need to adjust the MAIL_DIR and SPAMASS_DIR variable, depending on where your MAIL_DIR is located.
Next, we need to adjust the SPAMD options to use the virtual-config-dir (that’s the SPAMD name for this).
|
1 2 3 4 5 6 7 8 9 10 11 |
--- spamassassin.orig 2013-06-19 19:49:30.000000000 +0200 +++ spamassassin 2013-06-19 19:18:07.000000000 +0200 @@ -14,7 +14,7 @@ # make sure --max-children is not set to anything higher than 5, # unless you know what you're doing. -OPTIONS="--create-prefs --max-children 5 --helper-home-dir" +OPTIONS="--create-prefs --max-children 5 --helper-home-dir --virtual-config-dir=/var/lib/spamassassin/%d/%l -x -u mail" # Pid file # Where should spamd write its PID to file? If you use the -u or |
As you can see, I basically appended the following to the OPTIONS variable: –virtual-config-dir=/var/lib/spamassassin/%d/%l -x -u mail
Now, here’s a couple of pointers:
–virtual-config-dir=pattern
This option specifies where per-user preferences can be found for virtual users, for the -x switch. The pattern is used as a base pattern for the directory name. Any of the
following escapes can be used:%u — replaced with the full name of the current user, as sent by spamc.
%l — replaced with the ‘local part’ of the current username. In other words, if the username is an email address, this is the part before the “@” sign.
%d — replaced with the ‘domain’ of the current username. In other words, if the username is an email address, this is the part after the “@” sign.
%% — replaced with a single percent sign (%).
-u username, –username=username
Run as the named user. If this option is not set, the default behaviour is to setuid() to the user running “spamc”, if “spamd” is running as root.Note: “–username=root” is not a valid option. If specified, “spamd” will exit with a fatal error on startup.
Now, only a small adjustment is still needed. In order for the inbound mails to be scanned with the per-user db’s, you need to adjust postfix’s master.cf file, to run spamc with the per-user db.
|
1 2 3 4 5 6 7 8 9 10 11 |
--- master.cf.orig 2013-06-19 19:56:57.000000000 +0200 +++ master.cf 2013-06-19 19:57:09.000000000 +0200 @@ -115,7 +115,7 @@ # dovecot mail delivery dovecot unix - n n - - pipe - flags=DRhu user=vmail:mail argv=/usr/lib/dovecot/deliver -d ${recipient} + flags=DRhu user=vmail:mail argv=/usr/bin/spamc -u ${recipient} -e /usr/lib/dovecot/deliver -f ${sender} -d ${recipient} amavis unix - - - - 2 smtp -o smtp_data_done_timeout=1200 |
After that’s done (and a restart of postfix, spamassassin and dovecot) you should be the proud owner of a per-user dovecot/postfix/spamassassin implementation.
Well, I’m setting up spam/virus filter at the moment. Somewhere I found, that when doing so one should enable soft_bounce=yes in your /etc/postfix/main.cf. Now, once I finished setting up my mailing setup, I wanted to manually force the delivery.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Check for mails still in the mail-queue root:(eris.heimdaheim.de/mailing) PWD:~ Wed Jun 19, 17:57:10 [0] > mailq -Queue ID- --Size-- ----Arrival Time---- -Sender/Recipient------- B404F1B42C 2751 Wed Jun 19 17:58:01 christian.th.heim@gmail.com (user unknown) christian@heimdaheim.de C250F1B427 2770 Wed Jun 19 17:53:31 christian.th.heim@gmail.com (lost connection with 127.0.0.1[127.0.0.1] while receiving the initial server greeting) christian@heimdaheim.de -- 6 Kbytes in 2 Requests. |
Now, if you fixed the mail delivery, you just need to enter the following:
|
1 2 3 4 |
root:(eris.heimdaheim.de/mailing) PWD:~ Wed Jun 19, 17:57:10 [0] > postsuper -r ALL root:(eris.heimdaheim.de/mailing) PWD:~ Wed Jun 19, 17:57:11 [0] > postfix flush |
However if you want to delete the mail from the postfix queue:
|
1 2 |
root:(eris.heimdaheim.de/mailing) PWD:~ Wed Jun 19, 17:57:11 [0] > postsuper -d ALL deferred |